CentOS(Community Enterprise Operating System)是Linux发行版之一,它是来自于Red Hat Enterprise Linux(RHEL)依照开放源代码规定发布的源代码所编译而成。由于出自同样的源代码,因此有些要求高度稳定性的服务器以CentOS替代商业版的Red Hat Enterprise Linux使用。两者的不同,在于CentOS并不包含封闭源代码软件。CentOS 对上游代码的主要修改是为了移除不能自由使用的商标。2014年,CentOS宣布与Red Hat合作,但CentOS将会在新的委员会下继续运作,并不受RHEL的影响。CentOS和RHEL一样,都可以使用Fedora EPEL来补足软件。
一、概念
连接查询是关系数据库中最主要的查询,主要包括内连接、外连接和交叉连接等。通过连接运算符可以实现多个表查询。连接是关系数据库模型的主要特点,也是它区别于其它类型数据库管理系统的一个标志。在关系数据库管理系统中,表建立时各数据之间的关系不必确定,常把一个实体的所有信息存放在一个表中。当检索数据时,通过连接操作查询出存放在多个表中的不同实体的信息。连接操作给用户带来很大的灵活性,他们可以在任何时候增加新的数据类型。为不同实体创建新的表,然后通过连接进行查询。
二、使用
- 构造数据
1 | CREATE TABLE `table_join_two` ( |
- NLJ
- 查询语句
select * from table_join_one straight_join table_join_two on (table_join_one.a=table_join_two.a);- 如果直接使用 join 语句,MySQL 优化器可能会选择表 table_join_one 或 table_join_two 作为驱动表,这样会影响我们分析 SQL 语句的执行过程。所以,为了便于分析执行过程中的性能问题,我改用straight_join 让MySQL使用固定的连接方式执行查询,这样优化器只会按照我们指定的方式去 join。
- 在这个语句里,table_join_one 是驱动表,table_join_two 是被驱动表。
- 查看执行计划
explain select * from table_join_one straight_join table_join_two on (table_join_one.a=table_join_two.a);
- 查询语句
1 | *************************** 1. row *************************** |
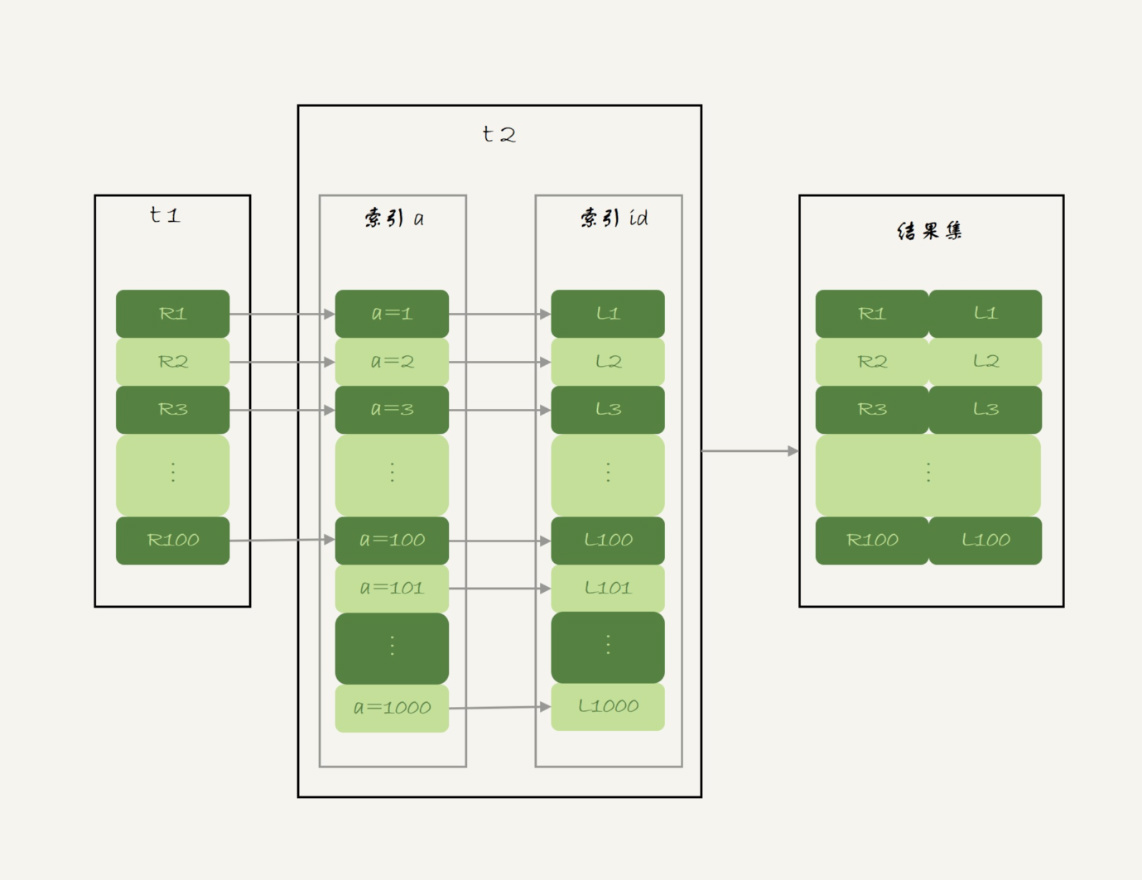
分析:在这条语句里,被驱动表 table_join_two 的字段 a 上有索引,join 过程用上了这个索引,因此这个语句的执行流程是这样的:
- 从表 table_join_one 中读入一行数据 R;
- 从数据行 R 中,取出 a 字段到表 table_join_two 里去查找;
- 取出表 table_join_two 中满足条件的行,跟 R 组成一行,作为结果集的一部分;
- 重复执行步骤 1 到 3,直到表 table_join_one 的末尾循环结束。
这个过程是先遍历表 table_join_one,然后根据从表 table_join_one 中取出的每行数据中的 a 值,去表 table_join_two 中查找满足条件的记录。在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以我们称之为“Index Nested-Loop Join”,简称 NLJ。
执行流程
如果一条 join 语句的 Extra 字段什么都没写的话,就表示使用的是 Index Nested-Loop Join(简称 NLJ)算法。
- BNL
- 查询语句
select * from table_join_one straight_join table_join_two on (table_join_one.a=table_join_two.b); - 查看执行计划
explain select * from table_join_one straight_join table_join_two on (table_join_one.a=table_join_two.b);
- 查询语句
1 | *************************** 1. row *************************** |
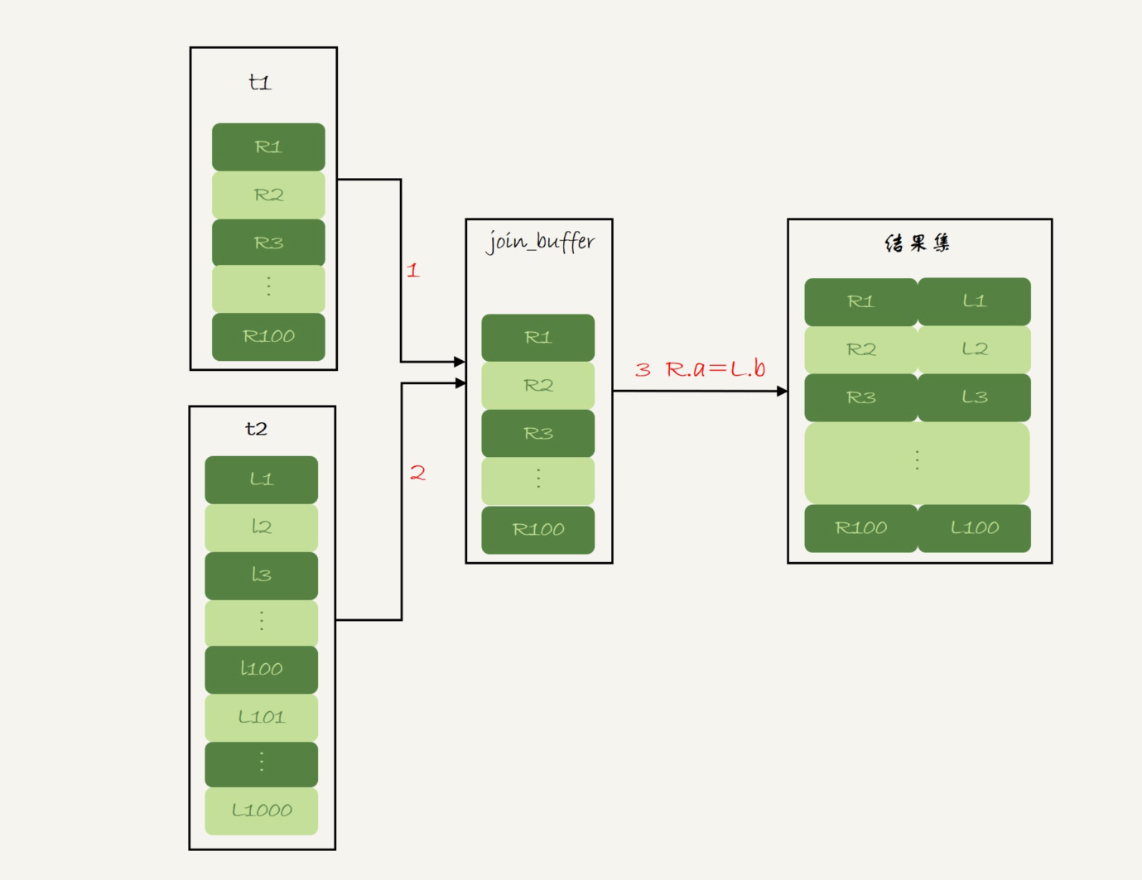
- 分析:在这个过程中,对表 table_join_one 和 table_join_two 都做了一次全表扫描,因此总的扫描行数是 1100。由于 join_buffer 是以无序数组的方式组织的,因此对表 table_join_two 中的每一行,都要做 100 次判断,总共需要在内存中做的判断次数是:100*1000=10 万次。这个语句的执行流程如下:
- 扫描表 t1,顺序读取数据行放入 join_buffer 中,直到 join_buffer 满了,继续第 2 步;
- 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
- 清空 join_buffer;
- 继续扫描表 t1,顺序读取数据放入 join_buffer 中,继续执行第 2 步。
- 执行流程